
From trained model to edge-ready deployment. Convert, optimise, validate, and benchmark AI models on real hardware — all through a no-code web interface.

Everything you need to go from a trained model to optimised edge deployment, in one platform.
Optimise and convert AI models without writing a single line of code. Intuitive web interface guides you through every step.
Track every optimisation step in an interactive model version tree. Compare branches, never lose track of what you've tried.
Test performance on actual edge devices: NVIDIA Jetson, Hailo accelerators, and standard CPU targets with live resource monitoring.
Six integrated capabilities that cover the full model optimisation lifecycle.
Convert between PyTorch, ONNX, TensorRT, and TFLite in a single click. Automatic validation ensures your converted model maintains expected behaviour.
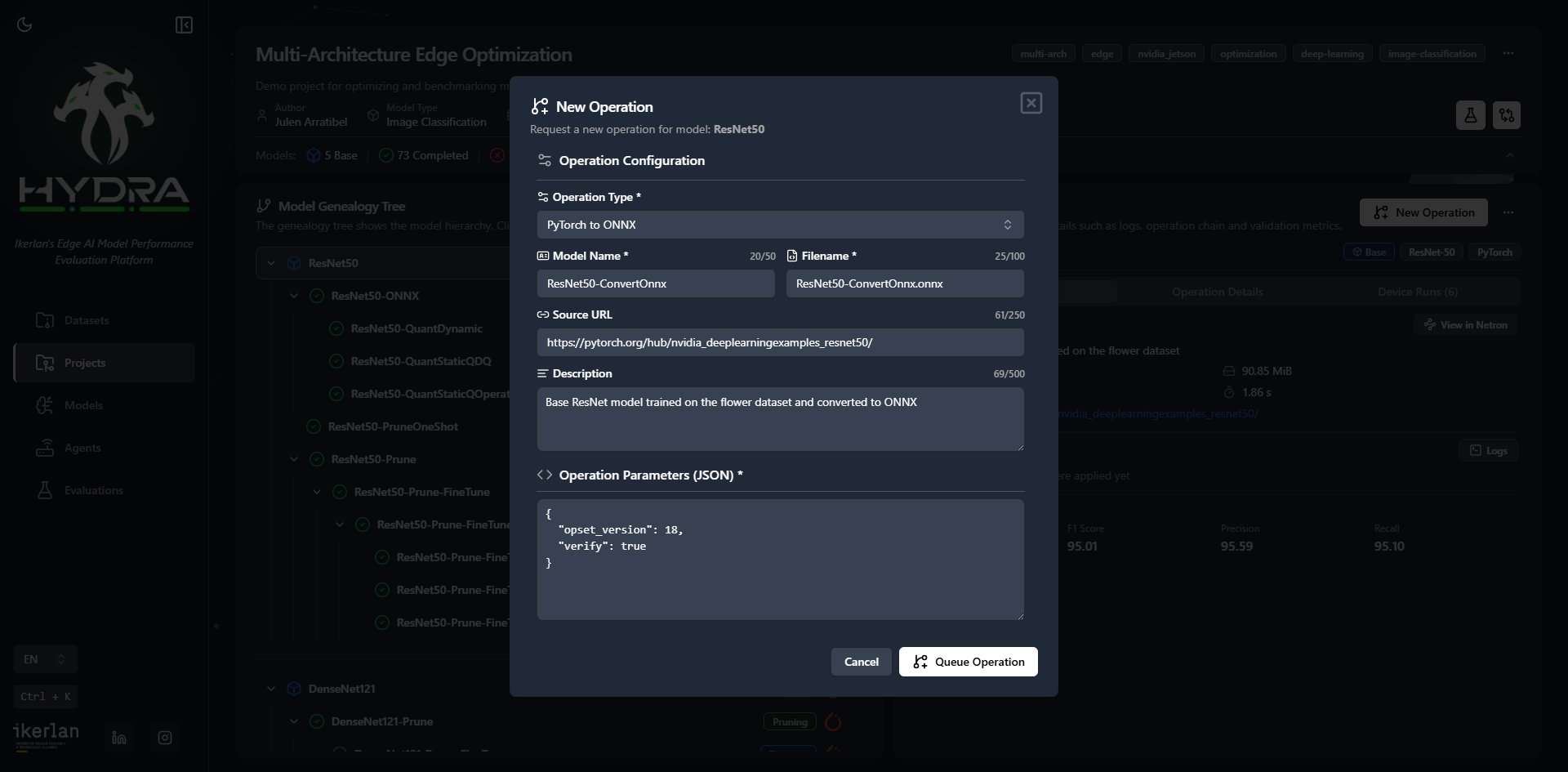
Apply pruning and dynamic or static quantisation to dramatically reduce model size and boost inference speed — with full control over parameters.
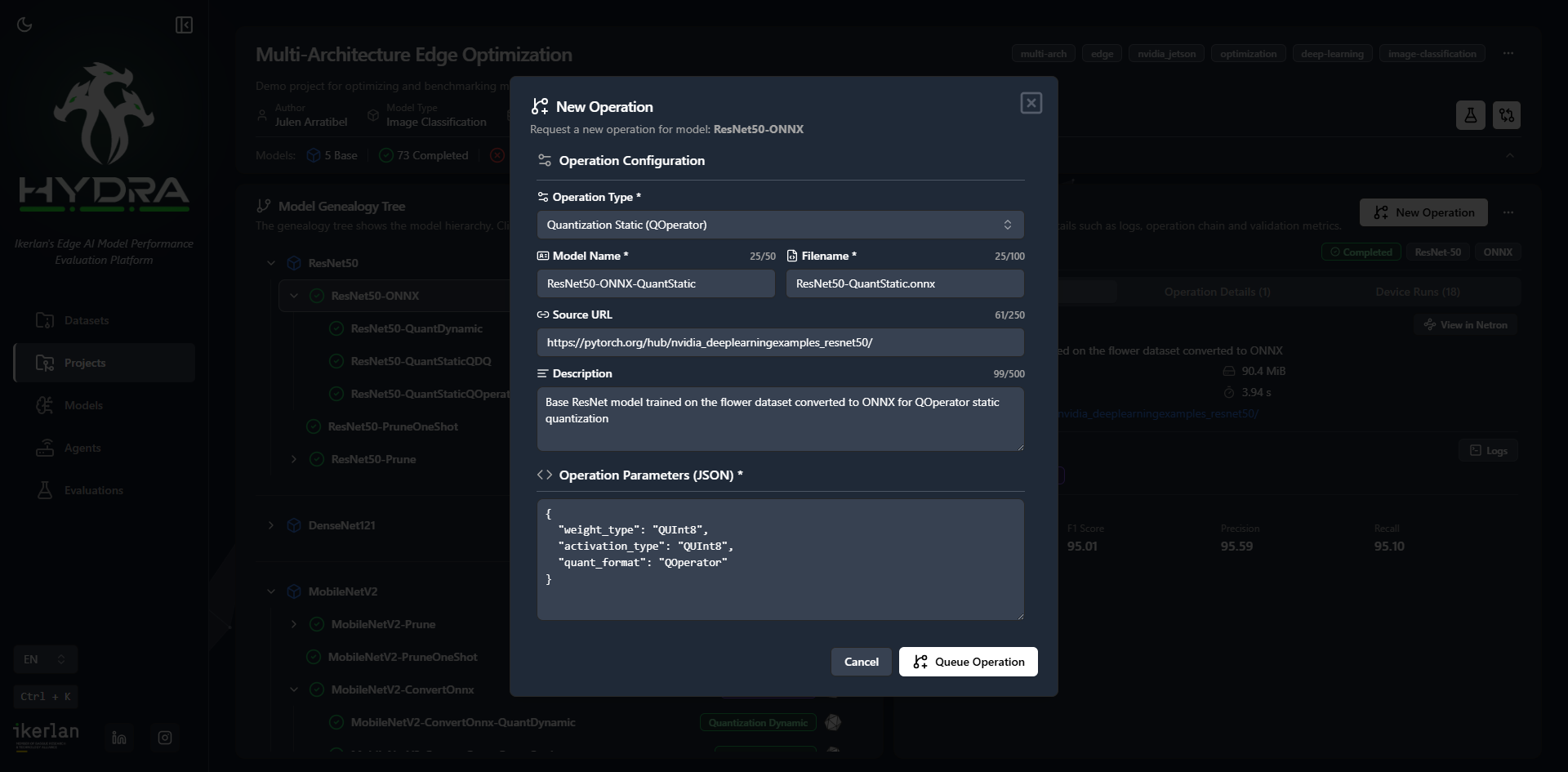
Verify accuracy after every operation with side-by-side metric comparisons. Ensure no regressions slip through before deployment.
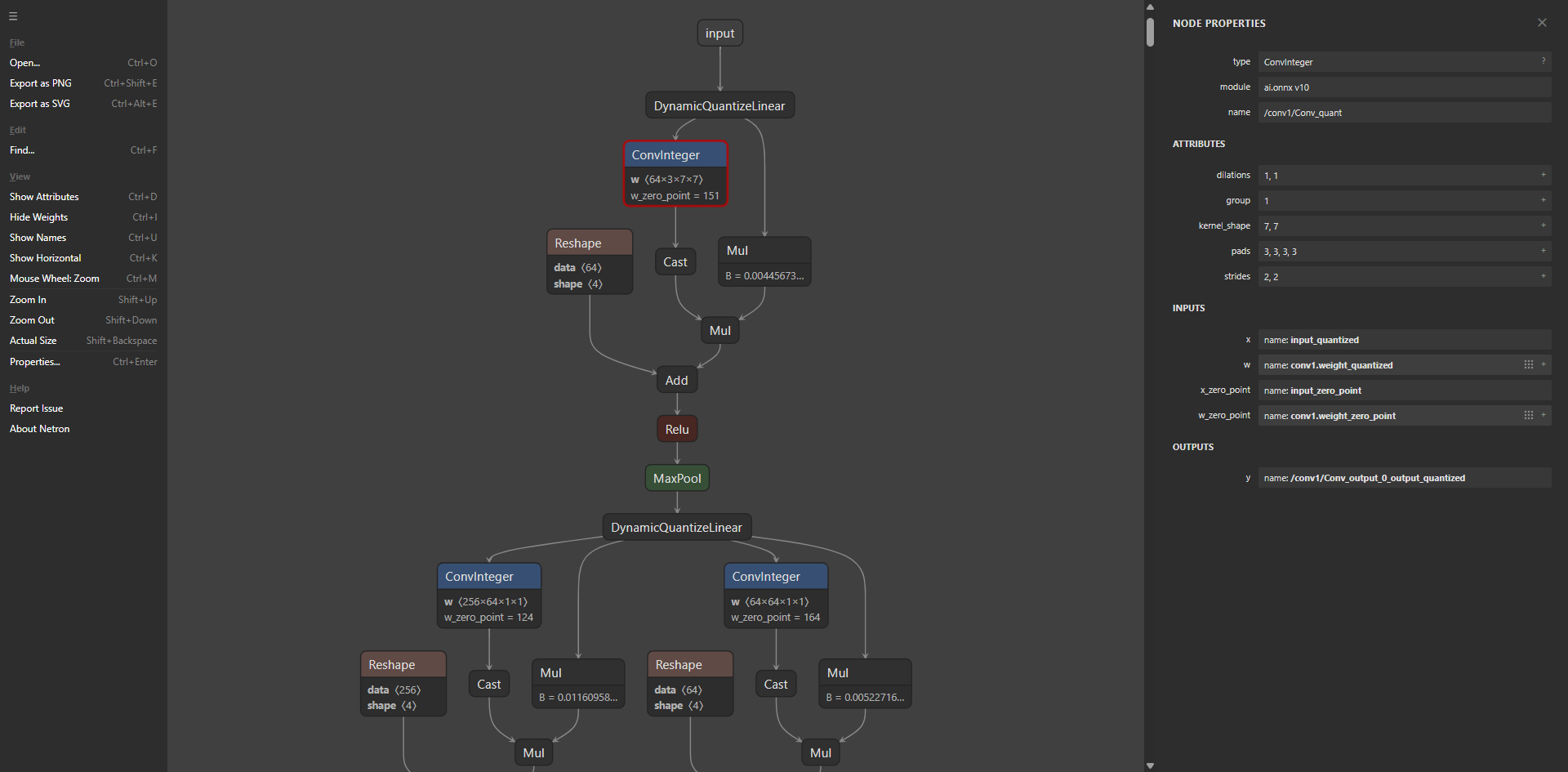
Inspect model graph architectures with an integrated Netron viewer — directly in your browser. Understand layer structure before and after optimisation.
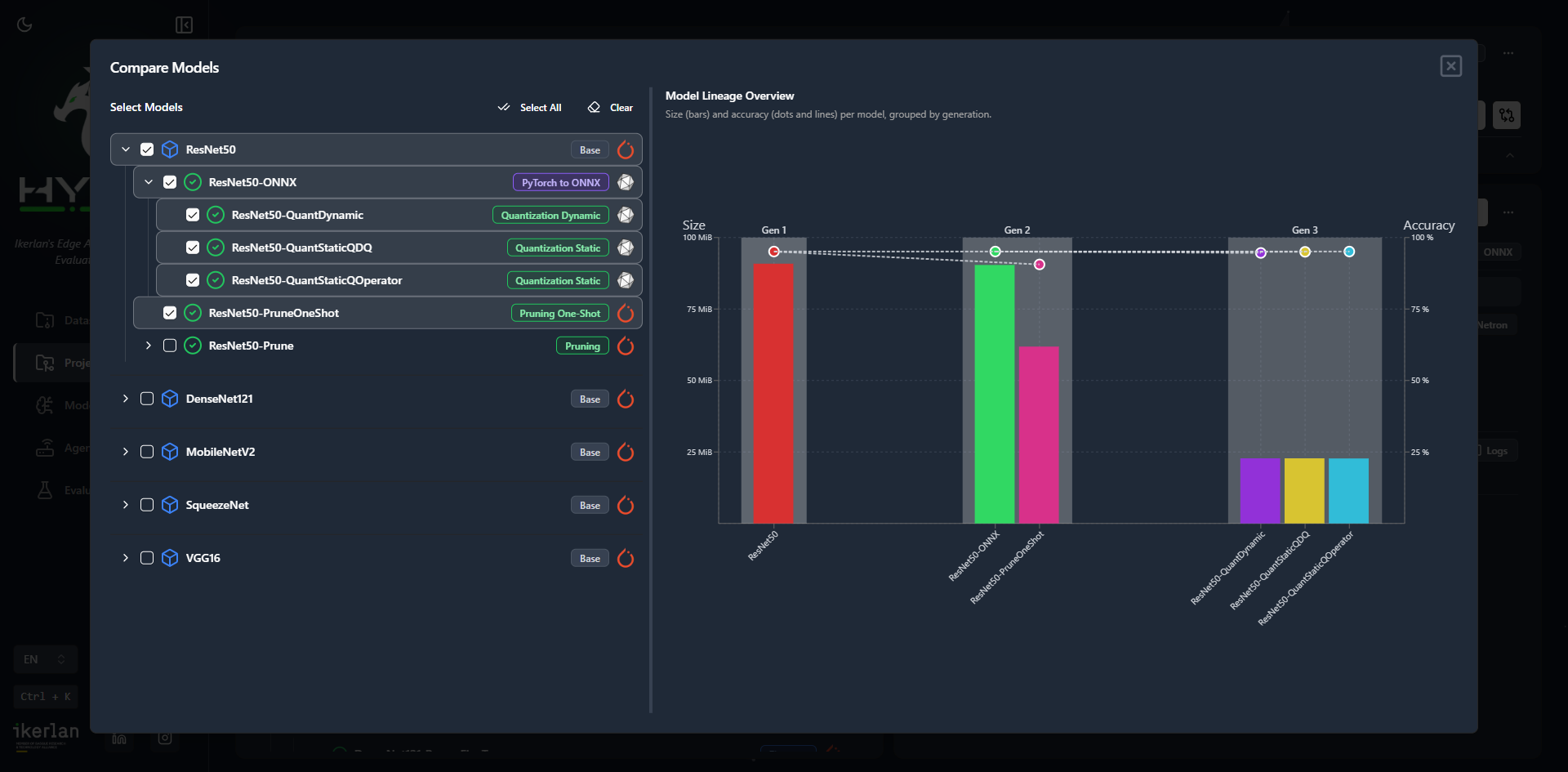
Visualise the full optimisation history as a branching version tree. Compare sibling models, explore alternative paths, and always know where each variant came from.
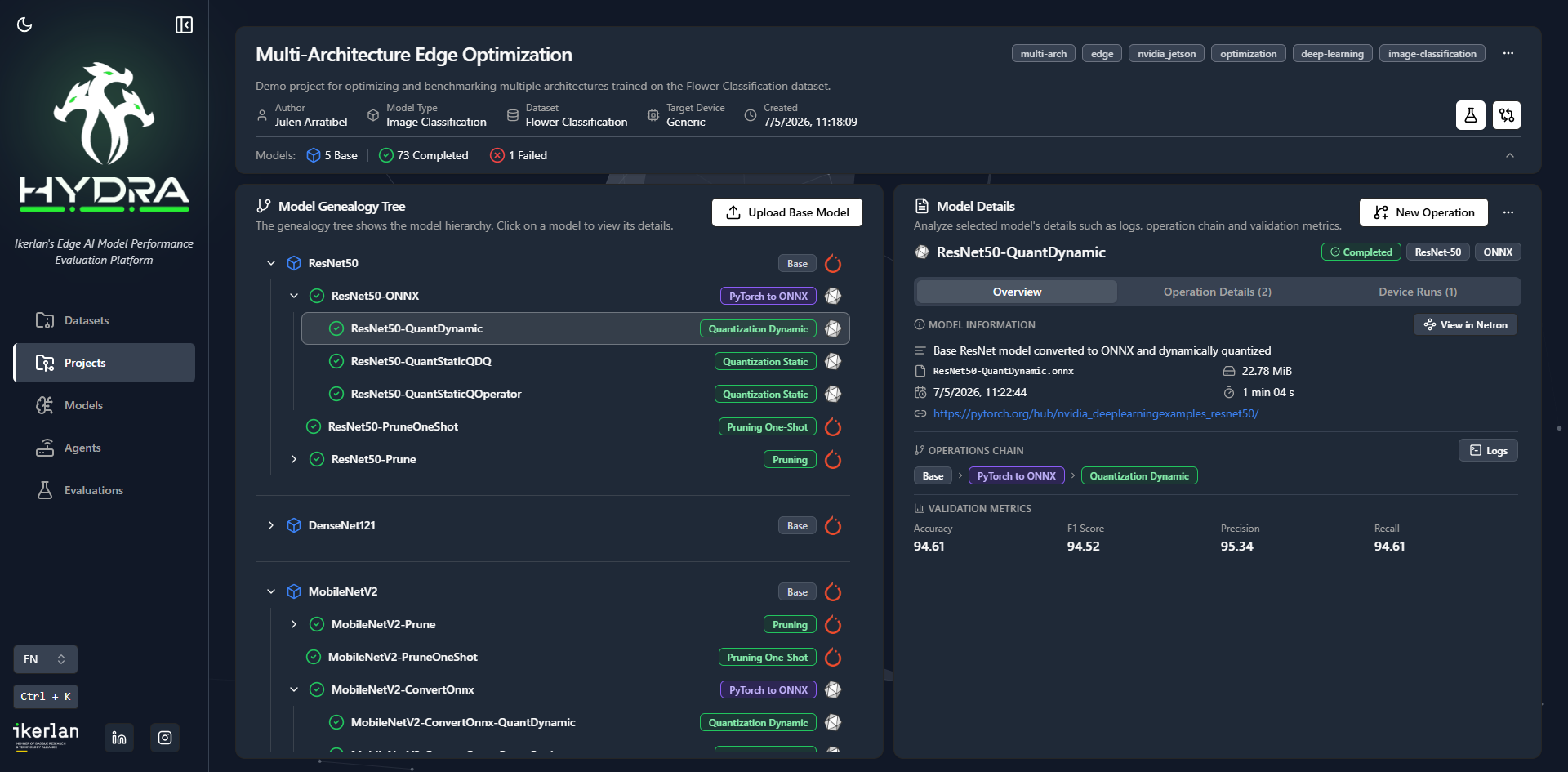
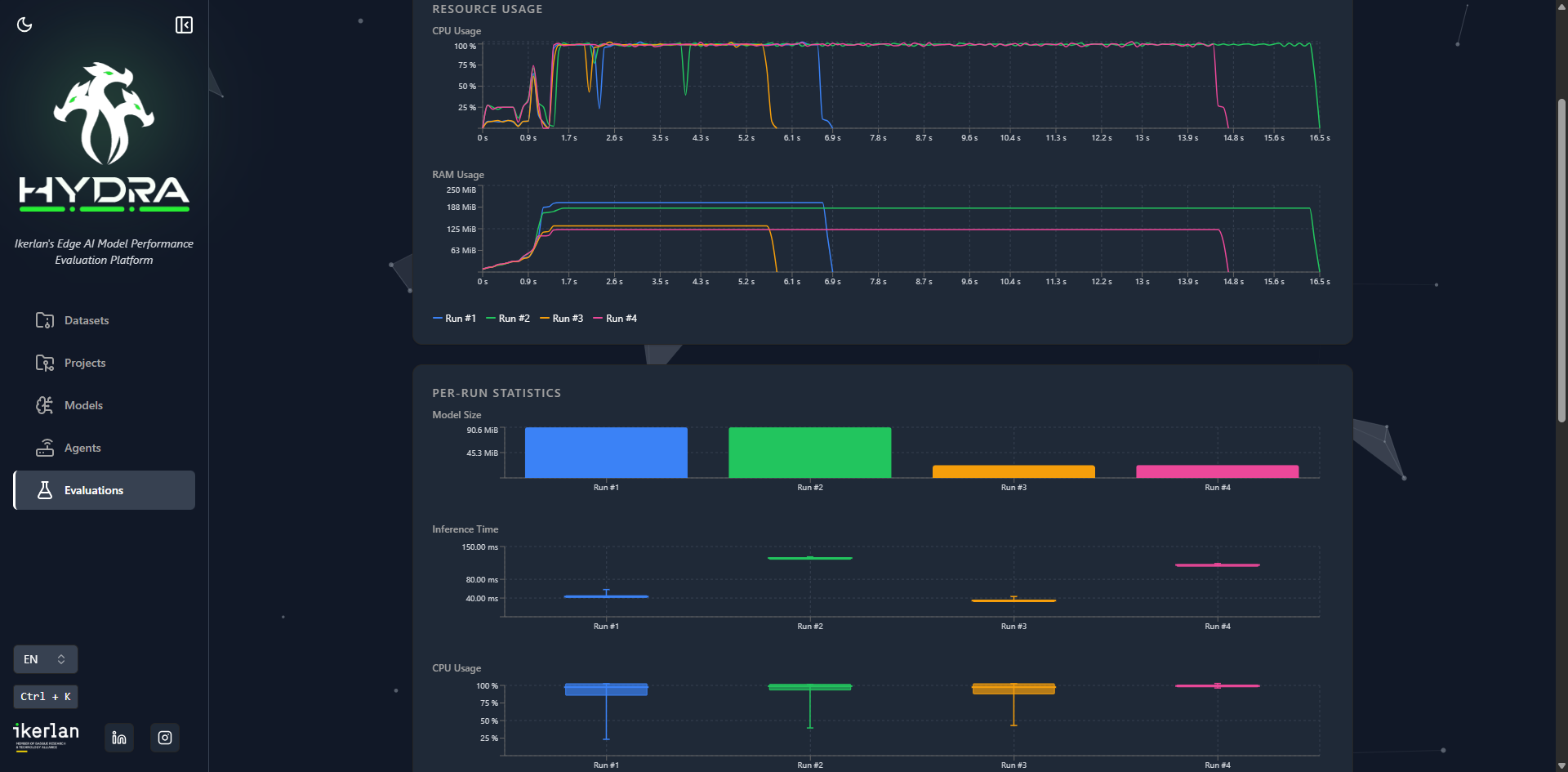
Benchmark models on real edge hardware with live resource monitoring. CPU, RAM, and GPU utilisation tracked in real-time during inference.
Work with the tools you already use and deploy on the hardware you need.
Four simple steps from trained model to edge-optimised deployment.
Upload your trained model in any supported format (PyTorch, ONNX, TFLite, etc.).
Choose a target framework and convert with automatic output validation.
Apply pruning or quantisation to reduce size and boost speed.
Test on real edge hardware, review metrics, and download your optimised model.
A modular, distributed architecture built for scalability and real-time processing.
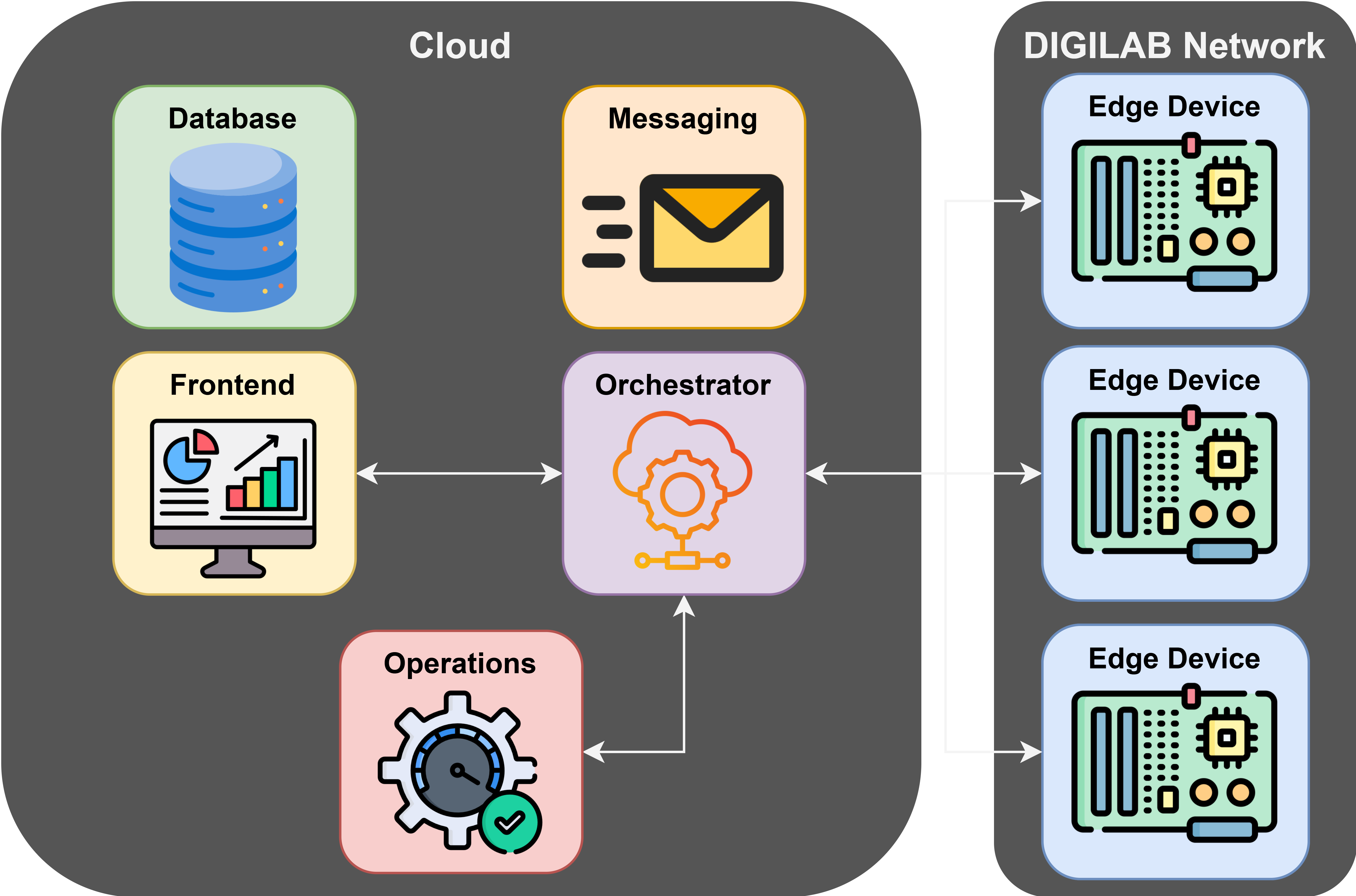
Each component has a single responsibility, communicating through well-defined interfaces.
Web application providing a no-code interface with real-time progress updates, interactive model version tree, and integrated model architecture viewer.
Central service handling business logic, REST APIs, and the real-time communication bridge for live progress updates.
Asynchronous ML pipeline running validation, conversion, pruning, quantisation, and fine-tuning tasks on GPU.
Persistent storage layer for model metadata, version history, and model binary artefacts.
Asynchronous messaging layer enabling decoupled communication between the orchestrator, optimisation service, and edge nodes.
Lightweight component running on each edge device that executes benchmark tasks and reports resource utilisation metrics in real time.
IKERLAN is a leading technology centre specialising in digital technologies, artificial intelligence, electronic embedded systems, cybersecurity, energy, and mechatronics. With over 50 years of experience in technology transfer, we develop innovative solutions that deliver real competitive advantage.
As a member of the BRTA (Basque Research & Technology Alliance) and part of Mondragon Corporation, we collaborate across sectors — from transport and energy to advanced manufacturing and health.
Visit IKERLAN →Get in touch with IKERLAN or the HYDRA development team to learn more about how HYDRA can accelerate your edge AI deployment pipeline. We're happy to arrange a demo or discuss your specific needs.